LLM 關鍵字
深入淺出解析 Key、Token、Query、Value、Inference、Hallucination、Overfitting 等 LLM 核心概念

最近在幫客戶查 vLLM 的 log,發現自己對於 LLM (大型語言模型) 關鍵字的認識仍有點模糊,所以決定整理一下一些常看到的用詞,希望對大家也有幫助。
以下會用比較淺顯易懂的方式介紹,並以「圖書館管理員」的比喻,來幫助大家更容易理解這些概念!
LLM 架構簡介 (以 Transformer 為例)
LLM 通常基於 Transformer 架構。我們可以將 Transformer 想像成一個由多個圖書館員 (Encoder 和 Decoder) 組成的團隊。
 來源:
來源: - Encoder (編碼器): 負責閱讀和理解輸入文本 (例如讀者的問題)。就像圖書館裡負責整理、分類書籍的館員。
- Decoder (解碼器): 負責生成輸出文本 (例如給讀者的回答)。就像圖書館裡根據讀者需求,撰寫摘要或報告的館員。
- Attention Mechanism (注意力機制): 這是 Encoder 和 Decoder 之間的橋樑。它讓 Decoder 知道在生成每個詞時,應該重點關注輸入文本的哪些部分。
Transformer 架構是 LLM 的基石,理解其組成部分和運作方式,有助於深入了解 LLM 的工作原理。
Attention 機制:圖書館的資訊檢索
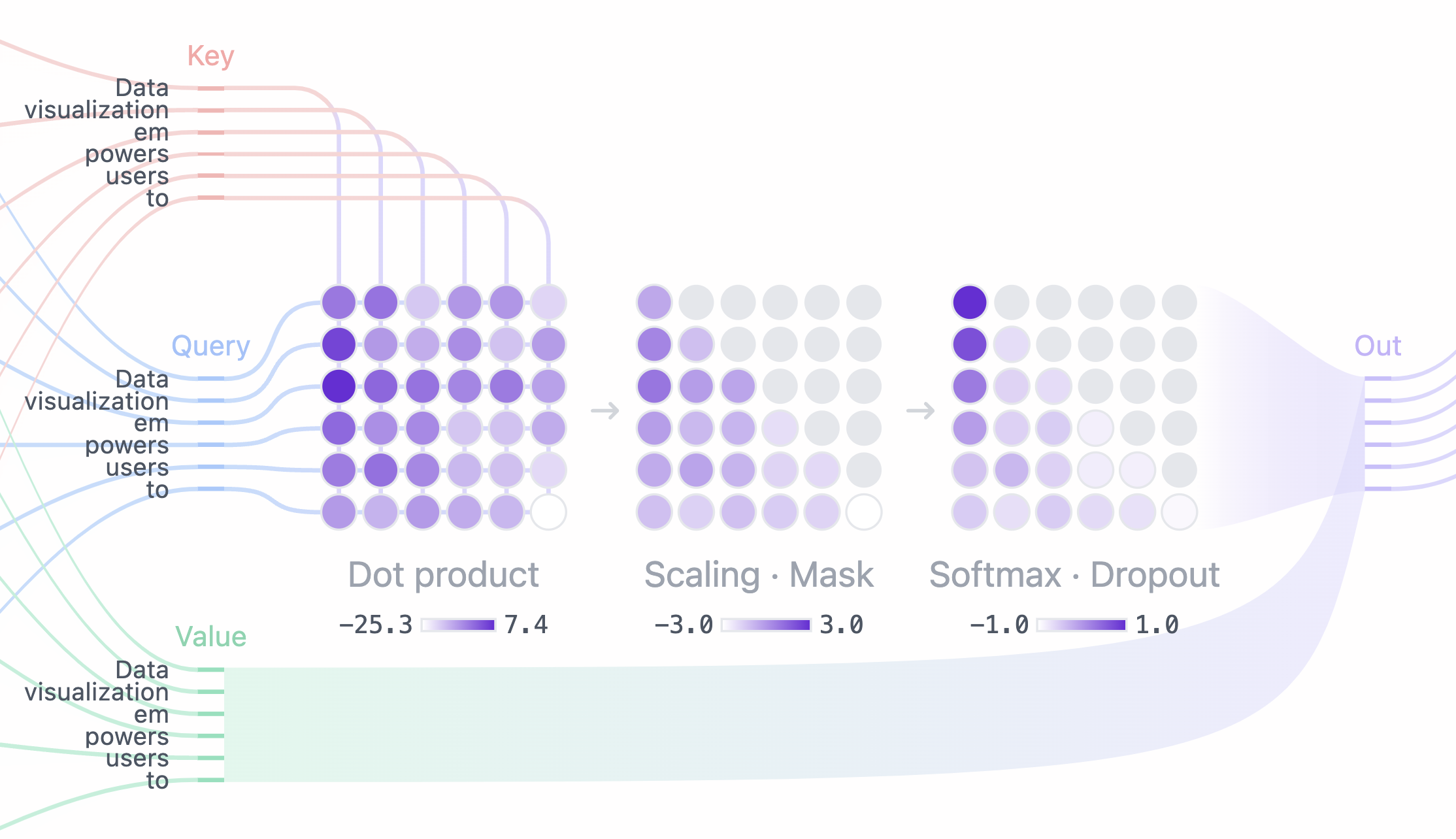
Attention (注意力) 機制是 LLM 的核心。想像一下,你是一位圖書館管理員,你的任務是幫助讀者 (使用者) 找到他們需要的資訊。
Query (查詢)
- 定義: 讀者向你提出的問題或需求。例如:「我想找關於文藝復興時期繪畫的資料。」
- 技術解釋: 在 LLM 中,Query 通常來自模型的解碼器 (decoder) 部分,表示目前需要關注的資訊。
- 比喻: 讀者的問題就是 Query。
Key (鍵)
- 定義: 圖書館中每本書的目錄、索引或標籤。它們能快速告訴你這本書的大致內容。
- 技術解釋: 在 LLM 中,Key 來自模型的編碼器 (encoder) 部分,表示輸入序列 (例如一段文字) 中每個部分 (例如每個單詞) 的「主題」或「概要」。
- 比喻: 書籍的目錄和索引就像 Key。
Value (值)
- 定義: 書籍的實際內容,包含所有詳細資訊。
- 技術解釋: 在 LLM 中, Value 也來自模型的編碼器部分,表示輸入序列中每個部分的「詳細內容」。
- 比喻: 書的內容就是 Value。
 圖片來源: transformer explainer
圖片來源: transformer explainer
- 讀者提出 Query: 「我想找關於文藝復興時期繪畫的資料。」
- 用 Query 比對 Key: 你會拿讀者的 Query 去和每本書的 Key (目錄、索引) 比較,找出相關性最高的幾本書。
- 你根據相關性加權 Value: 你會更仔細地閱讀那些相關性最高的書 (Value),並從中提取出與讀者 Query 最相關的資訊。
Query、Key 和 Value 的巧妙配合,讓 LLM 能夠像圖書館員一樣,從海量資訊中快速找到關鍵內容。
Token (詞元)
- 定義: 文本中被模型視為基本單位的片段。它可以是一個詞、一個字、一個標點符號,或一個詞的一部分 (subword)。
- 比喻: 如果把一本書比喻成輸入文本,那麼 Token 就像是書中的單字、標點符號,甚至是單字的一部分(例如 "un-", "-ing")。
- 重要性: LLM 處理文本時,是以 Token 為單位進行的。Token 的選擇會影響模型的性能和效率。
範例:- 輸入文本: "The quick brown fox jumps over the lazy dog."
- Tokenization (可能結果): ["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]
不同的 Tokenization 方法會產生不同的 Token 序列,進而影響模型的表現。
Inference (推論)
- 定義: 模型根據已學習的知識,對新的輸入數據進行預測或生成輸出的過程。
- 比喻: 讀者提出問題後,圖書館員根據自己的知識和館藏資料,給出答案的過程。
- 重要性: Inference 是 LLM 應用中最核心的環節。模型的 Inference 速度、準確性和成本,直接影響用戶體驗。
- 相關概念:
- Decoding (解碼): 在 Inference 過程中,將模型的內部表示轉換為人類可讀文本的過程。
- Sampling (採樣): 從模型預測的概率分佈中選擇下一個 Token 的方法 (例如 Top-k, Top-p)。
- Beam Search: 一種更高級的 Decoding 策略,同時維護多個候選序列。
Inference 是 LLM 的「魔力」所在,它讓模型能夠舉一反三,回答各種問題。
Parameters (參數)
- 定義: 模型內部可調整的變數。模型通過學習訓練數據來調整這些參數,以達到最佳性能。
- 比喻: 可以把參數想像成圖書館員的「知識」和「技能」。
- 知識: 包含對書籍內容、分類、作者等的了解。
- 技能: 包含快速檢索資訊、理解讀者需求、總結資訊等能力。
- 知識: 包含對書籍內容、分類、作者等的了解。
- 重要參數 (以 vLLM 為例):
max_new_tokens: 限制模型生成的文本長度。 * 比喻: 就像你告訴圖書館員:「寫一篇摘要,但不要超過 X 個字。」temperature: 控制生成文本的「隨機性」。- 比喻:
高
temperature:圖書館員更「奔放」,會使用不常見的詞彙,更有創意,但也可能出錯。 低temperature:圖書館員更「保守」,只使用熟悉的詞彙,更可靠,但也可能較單調。- 再加一個比喻:
temperature就像食譜中的「調味料」。高temperature就像加了很多辣椒,味道更刺激、多變,但也可能太辣;低temperature就像只加了鹽,味道比較穩定,但可能不夠豐富。
- 再加一個比喻:
- 比喻:
top_k: 每一步生成時,只考慮概率最高的 k 個 Token。- 比喻: 假設圖書館員每寫一個字,都會想出 10 個最可能的候選字詞 (Top 10)。
top_k= 3: 圖書館員只會從這 10 個字詞中,挑選最有可能的 3 個,再從這 3 個裡面選一個最適合的。 - 再加一個比喻:
top_k就像選秀節目中的「海選」。只讓評分最高的 k 位選手晉級。
- 比喻: 假設圖書館員每寫一個字,都會想出 10 個最可能的候選字詞 (Top 10)。
top_p: 每一步生成時,只考慮概率累加到 p 的 Token。- 比喻: 圖書館員每寫一個字,都會把所有可能的候選字詞,按照可能性從高到低排列。
top_p= 0.9: 他會一直把這些字詞的可能性加起來,直到總和達到 90% (0.9)。然後,他只會從這些加總到 90% 的字詞中挑選一個。 - 再加一個比喻:
top_p就像在自助餐中選菜。你不會每道菜都拿,而是會挑幾道你最喜歡的,直到你覺得盤子裡的菜夠了 (總「喜好程度」達到你的預期)。- 如果菜色普遍都很吸引你 (概率分佈平均),你會選比較多道菜。
- 如果只有少數幾道菜特別吸引你 (概率分佈集中),你可能只選那幾道就夠了。
- 比喻: 圖書館員每寫一個字,都會把所有可能的候選字詞,按照可能性從高到低排列。
repetition_penalty: 減少生成文本中的重複。- 比喻: 就像你告訴圖書管理員不要一直講一樣的話。
num_beams: (Beam Search) 同時考慮多個可能的生成路徑。- 比喻: 圖書館員在寫作時, 會在腦中同時構思多個版本的草稿 (假設是3個)。 每寫一個字, 都會基於這三個草稿去發想, 從中選出最好的3個草稿, 並持續下去。
stop: 指定停止生成的詞或序列。- 比喻: 就像你告訴圖書管理員看到。!? 就停下來
調整 Parameters 就像調整圖書館員的「工作模式」,可以影響生成文本的風格、長度和多樣性。
Loss Function (損失函數)
- 定義: 用於衡量模型預測結果與真實結果之間差距的函數。(主要用於訓練階段)
- 比喻: 假設你要訓練一位新的圖書館員助理。你會給他一些問題,讓他去找答案。然後,你會比較他的答案和你心中的「標準答案」之間的差距。差距越大,你就越「不滿意」(損失越大)。
- 目標: 訓練模型的目標是最小化損失函數,讓模型的預測結果盡可能接近真實結果。
- 常見損失函數: Cross-Entropy Loss (交叉熵損失)。
常見問題
Hallucination (幻覺)
- 定義: LLM 生成的內容看似合理,但實際上是錯誤的、無意義的,或者與事實不符。
- 比喻: 圖書館員自信滿滿地給出了一個答案,但這個答案是他自己編造的,圖書館裡根本沒有相關的資料。
- 產生原因:
- 模型過度自信。
- 訓練數據不足或存在偏差。
- 模型在生成過程中偏離了正確的上下文。
- 緩解方法:
- 使用更可靠的數據來源。
- 調整模型參數 (例如降低
temperature)。 - 引入外部知識庫 (例如檢索增強生成 RAG)。
- 對生成內容進行人工驗證。
Hallucination 是 LLM 的一個嚴重問題,需要特別注意和防範。
Overfitting (過擬合)
- 定義: 模型過度學習了訓練數據中的細節和噪聲,導致在訓練數據上表現很好,但在新的、未見過的數據上表現很差。
- 比喻: 圖書館員把每一本書都背得滾瓜爛熟,但他無法將這些知識應用到新的問題上,或者無法處理與書本內容稍有不同的情況。
- 產生原因:
- 模型過於複雜 (例如參數過多)。
- 訓練數據不足或不具代表性。
- 緩解方法:
- 使用更多、更多樣化的訓練數據。
- 簡化模型 (例如減少層數、減少參數)。
- 正則化 (Regularization) (例如 L1, L2 正則化,Dropout)。
- 早停 (Early Stopping)。
Overfitting 就像「書呆子」,只會死記硬背,缺乏靈活應變的能力。
Prompt Engineering (提示工程)
- 定義: 設計和優化輸入到 LLM 的提示 (Prompt),以引導模型生成更符合需求的輸出。
- 重要性: 好的 Prompt 可以顯著提高 LLM 的性能和準確性。
- 技巧:
- 明確指令: 清晰地說明你希望模型做什麼。
- 提供範例: 給出一些輸入-輸出範例 (Few-shot learning)。
- 逐步引導: 將複雜任務分解為多個簡單步驟 (Chain-of-Thought prompting)。
- 角色扮演: 讓模型扮演特定角色 (例如,「你是一位專業的文案寫手」)。
- 比喻: 就像你給圖書館員更明確的指示,例如:「請用簡潔、專業的語言,總結這本書的內容,並列出三個重點。」
- 範例:
Prompt Engineering 是一門藝術,也是一門科學。不斷嘗試和優化 Prompt,可以讓 LLM 更好地為你服務。
Evaluation Metrics (評估指標)
- 定義: 用於評估 LLM 性能的指標。
- 常見指標:
- Perplexity (困惑度): 衡量模型對文本的預測能力 (越低越好)。
- BLEU, ROUGE, METEOR: 用於評估機器翻譯、文本摘要等任務的指標 (越高越好)。
- Accuracy (準確率)、Precision (精確率)、Recall (召回率)、F1-score: 用於分類任務的指標。
- Human Evaluation: 真人評估
- 比喻: 就像圖書館會評估圖書館員的工作績效,例如讀者滿意度、回答問題的準確性等。
結構 ([INST], [s], [/s])
這些是特殊標記 (tokens),用於表示對話或指令式文本的結構,通常用於訓練或使用對話/指令模型。
[INST]: 表示 "instruction" (指令) 的開始。[s]: 表示對話輪次或輸入序列的開始。[/s]: 表示對話輪次或輸入序列的結束。
圖書館的一天
- 讀者提問: 讀者提出 Query (問題),圖書館員 (LLM) 運用 Inference (推論) 能力,根據 Key (目錄/索引) 找到相關的 Value (書籍內容),並根據設定的 Parameters (參數) 生成回答。但有時,圖書館員可能會過度解讀(overfitting),或是產生不存在的資料(Hallucination)。好的 Prompt Engineering 可以幫助讀者更精準的提問。
- 持續優化: 透過觀察使用者的回饋和日誌(log),並藉由調整 Parameters 或優化館藏 (訓練資料),可以持續提升圖書館員的服務品質。
參考資料
- Attention 機制: Attention Is All You Need (Transformer 原始論文) The Illustrated Transformer (圖解 Transformer)
- Tokenization: Hugging Face Tokenizers: How to Train a Tokenizer from Scratch
- Influence: 史丹佛大學的 CS324 課程
- vLLM 參數: vLLM Documentation
- Hallucination: Survey of Hallucination in Natural Language Generation
- Overfitting: Understanding Deep Learning Requires Rethinking Generalization
- Prompt Engineering: Prompt Engineering Guide
- 結構: Llama 2 論文