
How browser work?
💡 Main Goal: Understanding the underlying operations of modern browsers through this article
Key Questions:
- Browser tolerance for HTML writing errors?
- Why does everyone say reflow inevitably causes repaint, and should be avoided?
- How are CSS depth levels interpreted? Why are they never missed?
- In the same block, with elements having p⇒z-index:-1 and p⇒z-index:13 in order, which one gets painted first?
- What's the difference between reflow and repaint?
- Why does CSS parsing affect JS?
- Are browser engines and interpreters the same thing?
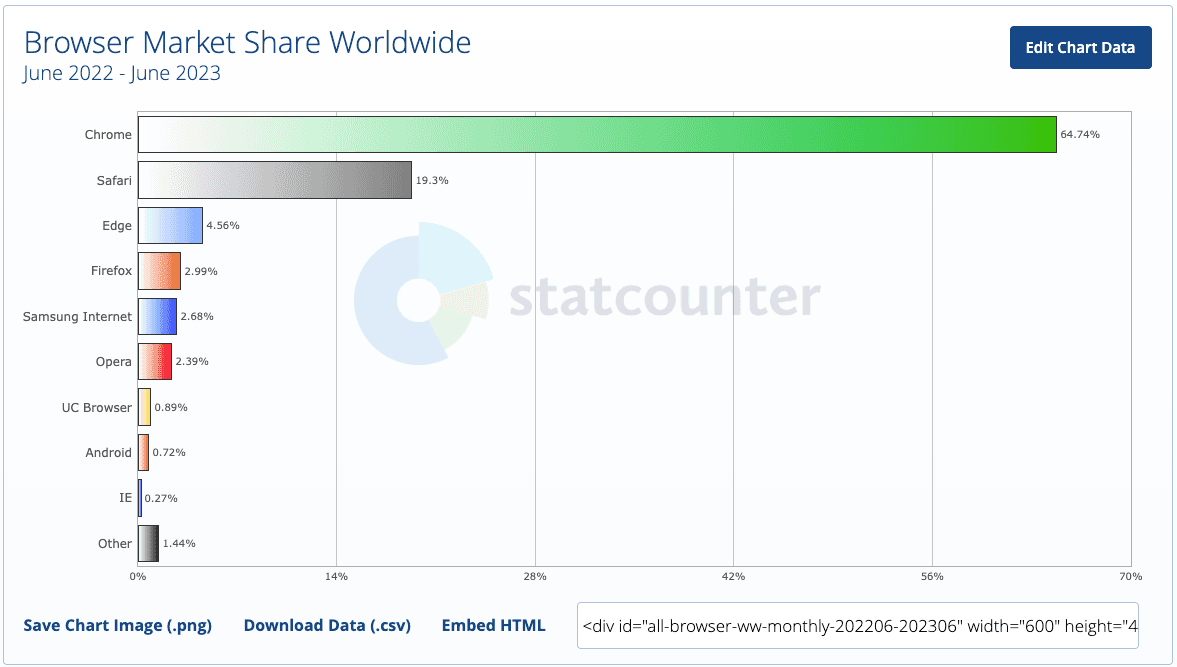
␦ Current Browser Usage Share
🀆 Browser Main Functionality
By parsing user Uniform Resource Identifiers (URI), browsers display requested content on pages. The specifications for returned pages are defined by W3C [Browser Wars].
Common and universal interface functions:
- URI address input interpreter (top input bar)
- Forward and back buttons
- Bookmark options
- Refresh and stop buttons
- Home button
::: details User Interface Browser user interfaces are not specified in any formal standards; they just come from good practices formed through years of experience and browsers imitating each other. :::
🀄︎ Browser High-Level Architecture (structure)
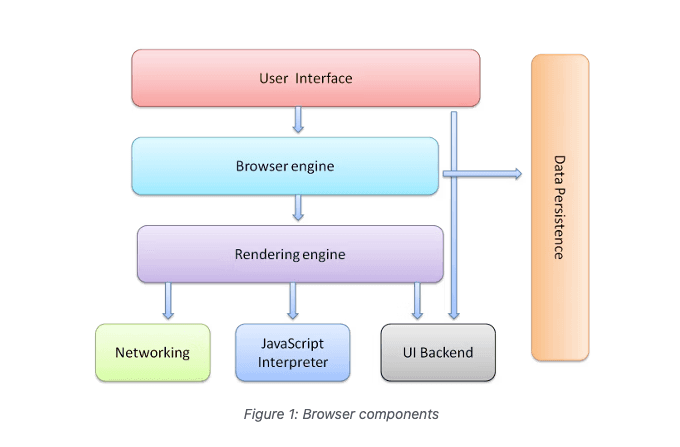
- UI Interface
- All UI interfaces except the request page
- Browser Engine
- Links operations between UI and rendering engine
- Google ⇒ Blink Mozilla ⇒ Gecko 1998 launch, longest running Internet Explorer ⇒ Blink Safari ⇒ WebKit proprietary branch
- Rendering Engine
- Renders required HTML CSS etc. to browser pages
- Networking
- Handles network calls like HTTP requests, platform-independent interface, using different implementations for different platforms!
- HTTP
java.net(Java platform)HttpClient(C#/.NET platform)requests(Python platform)NSURLSession(iOS/macOS platform)
- UI Backend
- Backend for drawing basic widgets (like combo boxes, windows, etc.). This backend provides a generic interface, not dependent on specific platforms. For example, selection boxes, input boxes, checkboxes, and windows.
- JavaScript Interpreter
- A program built into browsers for parsing and executing JavaScript code
- V8 (Chrome and other Chromium-based browsers), SpiderMonkey (Firefox), JavaScriptCore (Safari)
- Data Storage
- Used to save various data locally
- like cookies. Browsers also support localStorage, IndexedDB, WebSQL, and FileSystem
Browsers like Chrome use
multi-process architectureto run multiple instances of rendering engines ⇒ each Tab runs in a separate process.
🀪 Rendering Engines
Chrome uses WebKit. WebKit is an open-source rendering engine, originally created as an engine for Linux platforms, later modified by Apple to support Mac and Windows.
Main Process
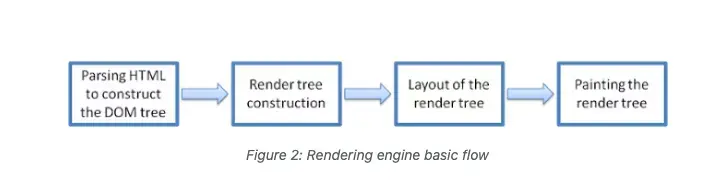
After networking processes downloaded resources, it begins parsing HTML and converting it to DOM tree, and parsing CSS to add style information to DOM tree to form Render tree.
Which becomes:

But before forming the above tree structure, there are several steps. Next we'll introduce this process and expand on each part.
This is a progressive process. If large calculations occur at any step, it will cause slower page rendering.
Detailed Flow Diagram
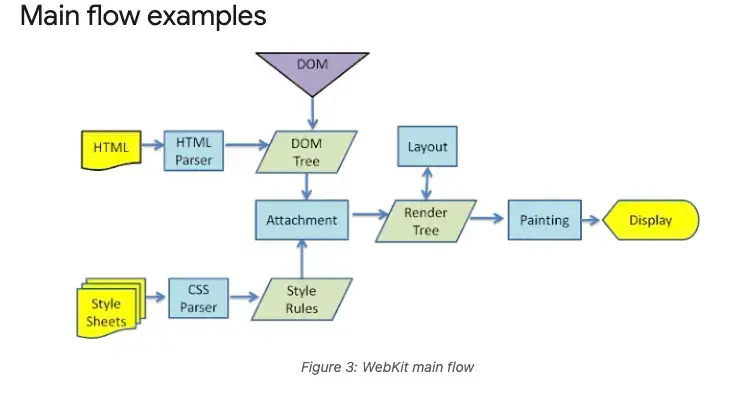
Gecko and WebKit now moved to Blink are commonly used engines with subtle differences in web rendering processes and terminology. Gecko uses Frame Tree, Reflow; while WebKit uses Render Tree, Layout, and Attachment connecting DOM and visual information. But ultimately both paint to pages the same way.
🀇 Parsers and Nodes (Parsing)
Parsing is the process of converting input text (HTML and CSS) into structured tree structures (DOM and CSSOM) according to language rules. It includes lexical analysis and syntax analysis, which can be implemented using top-down or bottom-up parsers. Parsers can be generated through automatic generation tools to help implement language parsing processes.
Major frontend frameworks also implement their own parsers to convert syntax sugar, all following similar parsing patterns.
Parsing results are usually node trees representing document structure, also called parse trees or syntax trees.
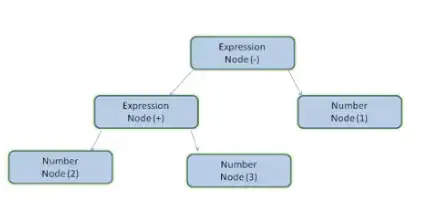
Each node represents an operator or operand, accurately representing the structure of the original expression.
Establishing Grammar
According to document rules, having deterministic grammar composed of lexical and syntax rules. It's called context-free grammar (Note 3).
Parsing Grammar ⇒ Parser←→Lexical Analyzer Combination
Lexical analyzer splits input into tokens, which are valid building blocks of the language.
Syntax analysis applies parsing according to language grammar rules.
Lexical analyzer (sometimes called tokenizer) and parser component responsible for analyzing document structure according to language grammar rules and building parse trees. Lexical analyzer knows how to remove irrelevant characters like spaces and line breaks.
Parsing process is iterative. Parser requests tokens from lexical analyzer, tries to match grammar rules, adds corresponding nodes to parse tree; if no match, saves tokens until finding matching rules, otherwise throws exception indicating invalid document.

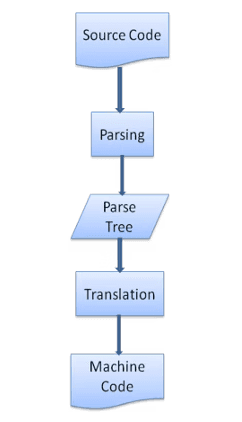
Translation to Machine Language
sourceCode → Parsinggrammar establishment and analysis → Translation to machine code0101, as shown below.
🀏 HTML Parser ⇒ DOM
HTML syntax defined by W3C is not suitable for traditional context-free grammar definition because HTML has tolerance, allowing omission of certain tags or start and end tags, making it difficult to parse using normal grammar. HTML is similar to XML, but its flexible tolerant syntax differs from XML's strict syntax, so XML parsers cannot directly parse HTML.
HTML Definition
HTML definition uses DTD (Document Type Definition) format, used to define SGML (Standard Generalized Markup Language) family languages.
DTD contains definitions of all allowed elements, attributes, and hierarchical structures.
DOM Tree
DOM is abbreviation for Document Object Model. It's object representation of HTML documents, the interface between HTML elements and external world, like JavaScript. Must conform to W3C specifications.
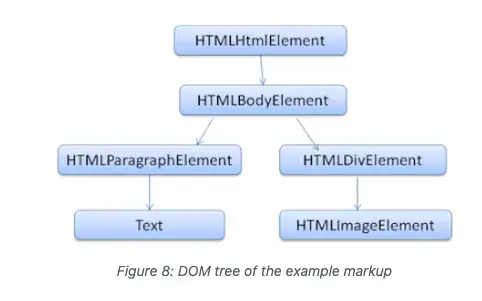
Parsing Algorithm
Due to HTML characteristics, traditional top-down or bottom-up parsers cannot be used. To handle HTML, browsers use custom parsers.
HTML parsing algorithm is detailed in HTML5 specification, containing two phases: tokenization and tree construction.
Tokenization is lexical analysis, parsing input into tokens including start tags, end tags, attribute names, and attribute values.
Tokenization passes tokens to tree constructor and consumes input characters one by one until input ends.
Imagine how to parse and construct DOM:
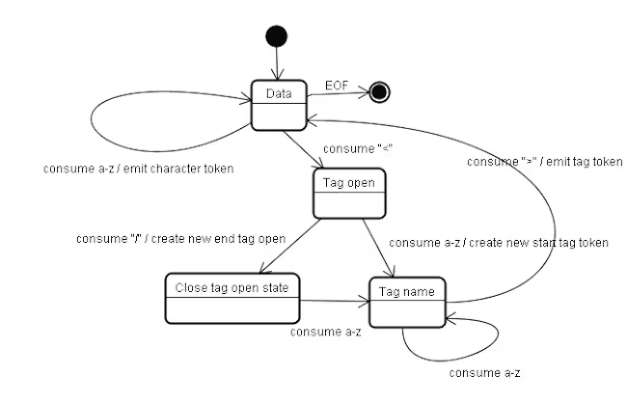
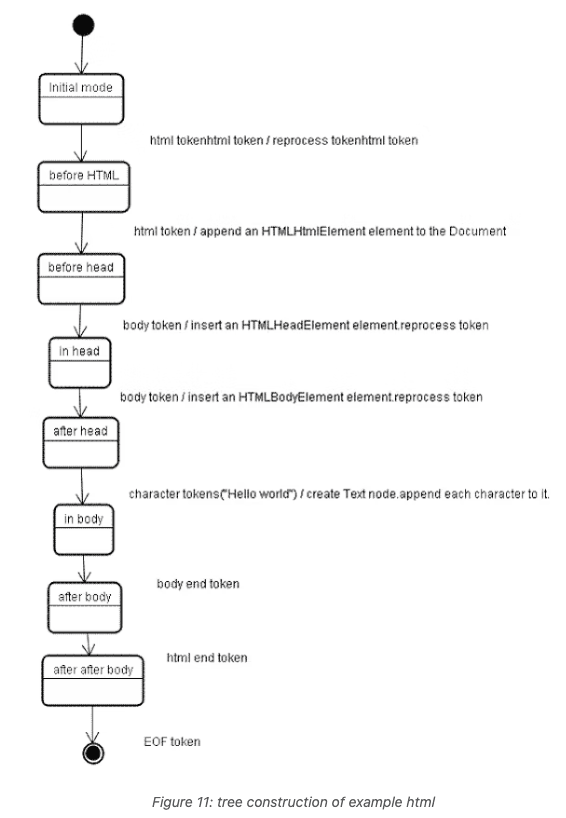
When parsing completes, document gets marked complete and executes documents that should execute after current document parsing loading
Browser Error Tolerance
Despite wrong closing tags, no errors are thrown.
HTML parser handles accordingly. Parser closes all tags one by one until reaching tags that prohibit adding that element.
Main responsibilities:
- When current element is explicitly prohibited from appearing in certain outer tags, need to close those tags.
- If forgot certain tags before current element (or tag is optional), need to close one by one until reaching position where element can be added.
- When trying to add block elements to inline elements, need to close all inline elements until reaching next higher-level block element.
- If above handling still cannot add element, continue closing tags until element can be added, or ignore the tag.
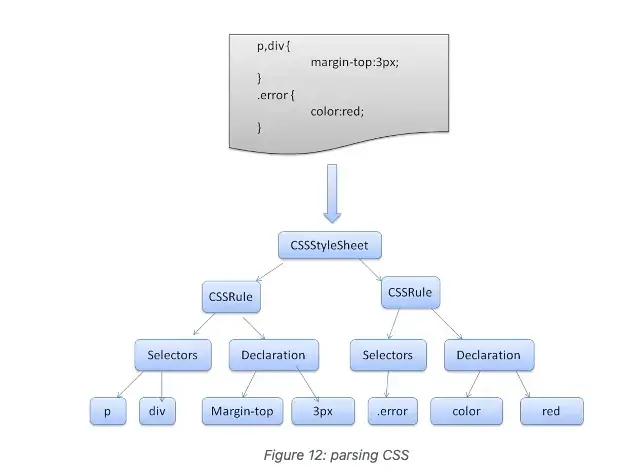
🀐 CSS Parser ⇒ CSSOM
CSS Object Model (CSSOM) is similar to DOM - both are tree structures, but they're independent data structures. Browser converts CSS rules into understandable and operable style mappings. Browser traverses each rule set in CSS, creating node trees based on CSS selectors with parent-child and sibling relationships. CSS is context-free grammar that can be parsed using shared parsers.
- Lexical grammar matches according to regex:
- Syntax analysis defined using BNFNote 4 for describing various CSS rules, selectors, properties, and other syntax elements.
Example gets matched to selector:
WebKit uses Flex/Bison parser generators to automatically create parsers from CSS grammar files. "A bottom-up shift-reduce parser" (Note 5)
Finally forms:
"Recalculate Style" in developer tools shows total time needed to parse CSS, build CSSOM tree, and recursively calculate computed styles.
🀘 Style Sheets and Script Execution Order
Preload Scanner
Preload scanner parses available content and requests high-priority resources like CSS, JavaScript, and web fonts. Thanks to preload scanner, we don't need to wait for parser to find external resource references before requesting them. It retrieves resources in background, so when HTML parser reaches requested resources, they may already be in transit or downloaded.
Script Loading Order
In web synchronous model, when parser encounters <script> tag, it expects scripts to be parsed and executed immediately. Document parsing stops until script execution completes.
- If script is external, must synchronously fetch resource from network, causing parsing to pause until resource fetching completes.
- Adding
deferattribute to<script>tag makes script execute after document parsing completes, not blocking parsing process. asyncattribute marks script as asynchronous. This means script loads and executes non-blockingly, not affecting document parsing, and can utilize different threads for parsing and execution, better improving web performance.
Speculative Parsing
When script is being parsed, another thread parses rest of document and finds other resources needing network loading and loads them.
Speculative parser only parses references to external resources (like external scripts, stylesheets, images). Doesn't perform DOM modifications main thread responsibility
Style Sheet Loading Order
Fetching CSS doesn't block HTML parsing or downloading, and doesn't modify DOM tree, but it blocks JavaScript parsing and causes errors. Because JavaScript often queries CSS properties and affects elements
Firefox blocks all scripts when stylesheets are still loading and parsing. WebKit only blocks scripts when scripts attempt to access certain style properties that might be affected by unloaded stylesheets.
Note:
HTML parser and CSS parser execute in parallel, coordinating during parsing and building documents to improve web loading efficiency and performance.
🀙 Render Tree Construction
Internal data structure created by browsers when processing web content, describing visible parts of web pages. DOM + CSSOM ⇒ Render Tree
Visual elements arranged in display order. Firefox calls render tree elements "frames". WebKit uses terms renderer or render object.
Following is renderer instance in render tree:
Relationship Between Render Tree and DOM Tree
Render tree doesn't correspond to DOM. If elements are affected by properties (non-visible DOM elements not inserted in render tree), some exceptions are renderers that cannot be represented by single objects (multiple line text or select).
Some render objects correspond to DOM nodes but not in same tree position. Float and absolute positioning elements are detached, placed in different parts of tree, and mapped to real frames.
⇒ This is why opening certain invisible nodes gets inserted in different positions.
Render Tree Construction Process
In WebKit, process of parsing styles and creating renderers is called "attachment". When processing HTML and BODY tags, render tree root node is constructed.
This root render object corresponds to containing block in CSS specification: topmost block containing all other blocks. Its dimensions are browser window's display area dimensions (viewport).
This root render object forms browser's rendering scope and serves as render tree beginning. Then traverses depth-first traversal(Note 6) entire DOM tree and CSSOM tree, merging them and building render tree describing web content and appearance.
Style Calculation
Building render tree requires calculating visual properties of each render object.
Difficulties:
- Style data is very large construct containing numerous style properties, potentially causing memory issues.
- Finding matching rules for each element can cause performance issues. For example: div div div div{ } how to find this element.
- How to apply complex cascade rules to various elements.
Solutions:
- Shared style data: WebKit nodes reference style objects (RenderStyle). In certain cases, these objects can be shared by nodes.
- Rule tree diagram: Firefox uses rule tree and style context tree to apply all matching rules in correct order and perform conversion from logical values to concrete values.
Storing rules is done lazily. Tree doesn't calculate every node at start, but when node style calculation is needed, computed path gets added to tree.
Dual tree structure also implemented in React for converting JSX back to DOM node nodes.
In WebKit, without rule tree, matching declarations are traversed four times. Multiple occurrences of properties are resolved according to correct cascade order, with last appearing rule overriding previous rules.
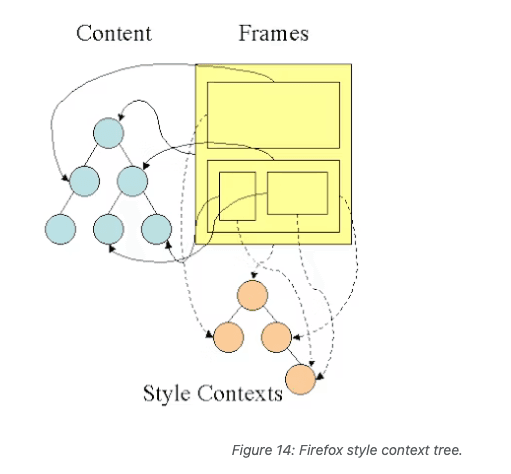
- Caching style information structures: All properties in structure can be inherited or non-inherited. Inherited properties are those that, if element doesn't define these properties, they inherit from parent element. Non-inherited properties (called "reset" properties) use default values when undefined. Helps speed up access and lookup. If underlying node doesn't provide definition for certain structure, cached structure from upper nodes can be used, saving calculation time. This approach also ensures consistency and validity of style information throughout document. (like borders or colors or font sizes)
- Selector hash maps: Rules added to multiple hash maps according to selectors (maps by id, by class name, by tag name, and general map for anything not in these categories).
- Style sheet cascade order: Defines rule application order, i.e., priority. Finally these priorities are sorted to resolve difficulty 2.
According to CSS2 specification, selector specificity is defined as follows:
- Count 1 if declaration is from 'style' attribute rather than rule with selector, otherwise 0 (= a).
- Count number of ID attributes in selector (= b).
- Count number of other attributes and pseudo-classes in selector (= c).
- Count number of element names and pseudo-elements in selector (= d).
- Concatenating four numbers a-b-c-d (in large number system) gives specificity.
🀡 Layout
Once render tree is built, layout begins. Render tree determines which nodes to display (even invisible ones) and their computed styles, but doesn't include size or position of each node. ⇒ Layout calculates position and size. HTML uses flow-based layout model, which is a recursive process.
All renderers have "layout" or "reflow" method. Each renderer calls layout method of children needing layout. ⇒ First time determining size and position of each node is called layout. Subsequent recalculations are called reflow. ::: info Root renderer position is 0,0, its dimensions are viewport - visible part of browser window. :::
Dirty Bit System
To avoid full layout for every small change, browsers use "dirty bit" system. Two types of flags "dirty" and "children are dirty" distinguish self and children.
Global and Incremental Layout
Global calculation triggered on entire render tree:
- Global style changes affecting all renderers, like font size changes.
- Screen size is adjusted
Only renderers marked as dirty bits get laid out.
Incremental layout calculation: (asynchronous)
- Additional content from network and added to DOM tree
Asynchronous and Synchronous Layout
In Firefox and WebKit, incremental layout is asynchronous. Both use scheduler to trigger batch execution of "reflow commands". Incremental layout will re-layout renderers marked as "dirty" (needing re-layout). This allows layout updates to complete in separate time slice without immediately interrupting web rendering process.
Layout Optimization
In certain cases, when layout is triggered, such as "resize" or renderer position changes (not size), renderer size is taken from cache rather than recalculated.
Sometimes only subtree is modified, layout doesn't start from root node. This can happen when only local changes don't affect surroundings, like inserting text into text field (otherwise every keystroke would trigger layout from root node).
Layout Process Pattern
- Parent renderer determines its own width.
- Parent renderer traverses child renderers and performs following:
- Places child renderer (sets its x and y position).
- If needed, calls child renderer's layout process - this might be because child renderer's content changed, or during global layout, or other reasons.
- Calculates child renderer's height.
- Parent renderer uses child renderers' accumulated height plus margin and padding heights to set its own height - this will be used by parent renderer's parent renderer.
- Sets parent renderer's "dirty" flag to false, indicating layout is complete.
Additionally there are width calculation and layout interruption not shared here.
🀀 Painting
Painting can split elements in layout tree into different layers. Promoting content to layers on GPU (rather than CPU main thread) can improve painting and repainting performance. Specific properties and elements create layers, including video and canvas elements, any elements with opacity, 3D transforms, will-change CSS properties, and several other reasons. These nodes will be painted to their own layers, including descendants, unless descendants need their own layers for above reasons.
In painting phase (FMP), traverse render tree and call renderer's "paint()" method to display content on screen.
Painting can be global or incremental. Incremental painting only repaints changed parts, while global painting repaints entire render tree.
To ensure smooth scrolling and animation, everything occupying main thread, including calculating styles, reflow and painting, must let browser complete within 16.67 milliseconds.
Painting Order and Display Lists
Defined by CSS2, affects element stacking order in stacking context and influences painting order. Firefox uses display lists to optimize painting process, traversing render tree only once to paint relevant elements.
Firefox traverses render tree and builds display list for painted rectangles. It contains renderers related to rectangle in correct painting order (renderer's background, then border, etc.).
- background color
- background image
- border
- children
- outline
Dynamic Changes
Rendering engine attempts minimal possible action when responding to changes. For example, changing element color only repaints that element itself, while changing element position may trigger re-layout and painting of element, its children, and possibly siblings. Adding DOM nodes will cause node layout and painting. Larger changes like increasing "html" element font size will cause cache invalidation, re-layout and painting of entire render tree.
Rendering Engine Threads
Rendering engine is single-threaded. Except for network operations, almost all operations occur in single thread. Main thread is event loop waiting for and processing events (like layout and painting events).
Painting engine may have limited thread count, while network operations can be executed by multiple parallel threads.
Event Loop
This is infinite loop keeping process alive. It waits for events (like layout and painting events) and processes them.
🀁 Compositing
When different parts of document are painted in different layers and overlap each other, compositing must be used to ensure they display on screen in correct order and content renders correctly.
As page continues loading resources, reflows may occur (recall our example's late-arriving image). Reflow will trigger repaint and re-composite. If we define image dimensions in advance, no reflow needed, only layers needing repainting will update and re-composite if necessary. But we didn't include image dimensions! When image is fetched from server, rendering process returns to layout step and restarts from there.
🀂 Display
When all previous steps are processed, it's the page display stage. This stage follows these steps:
- Parse source code and create DOM Tree.
- Determine current media type

- Retrieve all style sheets associated with current media type
- Assign properties to DOM Tree elements through mechanisms suitable for current media type (according to style calculation rules)
- Calculated parts of various properties depend on formatting algorithms applicable to target media type. For example, if target media is screen, user agent will apply visual formatting model
- Transfer formatting structure to target media (like print results, screen display, speech conversion), so we can see page content.
DOM Tree generates formatting structure, which is not necessarily tree structure and contains more or less content (due to previously mentioned display properties that might turn off certain structure generation). Lists can generate more information in formatting structure: list element content and list style information, etc.
Next introduce some common property descriptions:
Canvas
"Canvas" describes "space where formatting structure is rendered". Canvas is infinite in each spatial dimension, but rendering usually occurs in finite area of canvas, set by user agent(Note 1) according to target media.
CSS Box Model
Describes rectangular boxes generated for elements in DOM tree and laid out according to visual formatting model.
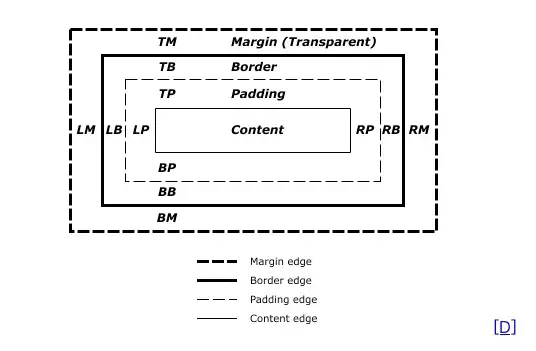
Each box has content area and optional surrounding padding, border, and margin areas. All elements have "display" property determining type of box to be generated.
Positioning Scheme
- Normal: Objects positioned according to their position in document. This means its position in render tree is like its position in DOM tree, laid out according to its box type and dimensions
- Float: Object first laid out like normal flow, then moved as far left or right as possible
- Absolute: Object placed in render tree at different position than in DOM tree
Box Types Positioning (abbreviated below)
Layered Representation
z-index is CSS property used to specify element's display order in stacking context, i.e., in third dimension of stacking, also called "z-axis". This property affects element display order when overlapping.
Elements are divided into multiple stacks (called stacking contexts) Note 2.
In each stack, elements at back are painted first, while elements at front, closer to user, are painted on top. If elements overlap, front elements will obscure back elements.
🀃 Conclusion
Browser is complex software system responsible for converting HTML, CSS, and JavaScript code on web pages into content understandable to users. Browser working principles can be summarized as follows:
- Painting order: Browser paints web pages according to HTML and CSS rules, laying out and rendering from top to bottom, left to right. During painting, browser considers element hierarchy, size, position, borders, padding and other factors to ensure web appearance and layout meet design requirements.
- Dynamic changes: Rendering engine performs minimal possible actions when responding to web changes, for example changing element color only repaints that element itself. This minimizes painting overhead and improves web performance and response speed.
- Rendering engine threads: Rendering engine is single-threaded. Except for network operations, almost all operations occur in single thread. This means browser can better control painting process, reducing unnecessary painting and response delays.
- Event loop: Event loop is infinite loop keeping process alive. It waits for and processes events. Event loop is very important mechanism in browsers, responsible for handling user interactions, animations, timers and various other events, ensuring normal web operation.
- Compositing: When different parts of document are painted in different layers, compositing must be used to ensure they display on screen in correct order. Compositing is very complex process in browsers, involving calculations of multiple layer merging, displacement, transparency, etc., to ensure web presentation meets expectations.
- Visual display: Browser parses HTML, creates DOM Tree, determines media type, retrieves and assigns styles, finally transfers formatting structure to target media, presenting page content. In this process, browser considers many factors like screen size, resolution, display mode, font size, etc., to ensure web content and layout meet user expectations.
🔑 Additionally, this article introduces related terms including user agent, stacking context, and context-free grammar. These terms are very important for understanding browser working principles and optimizing web performance.
In summary, browser is very complex system that parses and paints HTML, CSS, and JavaScript code on web pages from different angles, finally presenting users with web pages with good appearance and performance.
Understanding browser working principles and related terms can help us better develop and optimize web pages, improving user experience.
🀅 Term Supplements
User Agent: Software application or code that represents users and interacts with websites or network services in internet environment. It's a client that can send requests to servers and parse responses. Browsers are most common user agents, but other applications or code like web crawlers, robots, and automation scripts can also serve as user agents.
User agents are responsible for processing and presenting website content, parsing and presenting website HTML, CSS, JavaScript and other resources to users. They also pass information about user agent itself to servers when making web requests, such as browser type, version, operating system, etc. This information is usually used to optimize website presentation and provide better user experience.
User agents play important role in internet because they enable users to interact with websites and network services in friendly way, while also providing important data about user information to help websites optimize their content and functionality.
Stacking Contexts: Mechanism for handling element overlapping display. When elements overlap, their display order is determined by stacking context, not just their position in DOM or document flow order.
Context-Free Grammar: Formal grammar used to describe structure of natural or programming languages. It's memoryless grammar, meaning each rule application is independent of other rule applications, not dependent on lexical or sentence context.
BNF: (Backus-Naur Form) symbolic notation for describing programming language grammar.
Shift-Reduce Parser: Technique used for syntax analysis (Parsing), commonly used to parse grammar structures of programming languages, markup languages, etc. It's a top-down syntax analysis method for converting input sequences (like code or text) into parse trees or abstract syntax trees.
Depth-First Traversal: Common traversal method that starts from root node, sequentially traverses each node's children until reaching deepest part of tree, then returns and continues traversing other branches.
Sources
Populating the page: how browsers work - Web performance | MDN