LLM Keywords
A beginner-friendly explanation of core LLM concepts like Key, Token, Query, Value, Inference, Hallucination, Overfitting, and more

While helping a client review vLLM logs recently, I realized that my understanding of some key LLM (Large Language Model) terms was still a bit fuzzy. So I decided to organize and explain some commonly seen terms—hopefully, it’ll be helpful for others too.
I'll use simple, easy-to-understand language along with a "librarian" analogy to help make these concepts more approachable!
LLM Architecture Overview (Using Transformer as an Example)
LLMs are usually based on the Transformer architecture. You can imagine a Transformer as a team of librarians made up of encoders and decoders.
 Source: Transformer Architecture
Source: Transformer Architecture
- Encoder: Reads and understands the input text (like a reader’s question). Think of it as the librarian who organizes and categorizes books.
- Decoder: Generates the output text (like answering the reader). Think of it as the librarian who writes summaries or reports based on the reader’s request.
- Attention Mechanism: Acts as the bridge between encoders and decoders. It helps the decoder focus on the most relevant parts of the input while generating each word.
The Transformer is the backbone of LLMs. Understanding its components and workflow helps us better grasp how LLMs work.
Attention Mechanism: Library Information Retrieval
The attention mechanism is the heart of LLMs. Imagine you're a librarian, and your job is to help readers find the information they need.
Query
- Definition: The question or request the reader gives you. Example: “I want information about Renaissance paintings.”
- In LLMs: The query is usually generated by the decoder and represents what the model is currently focusing on.
- Analogy: The reader’s question is the query.
Key
- Definition: The table of contents or index for each book—used to quickly understand what each book is about.
- In LLMs: The key comes from the encoder and represents the “summary” or “topic” of each input token.
- Analogy: The book’s table of contents is the key.
Value
- Definition: The actual content of the book—full of details and insights.
- In LLMs: Also from the encoder, it holds the detailed information for each token in the input.
- Analogy: The book’s content is the value.
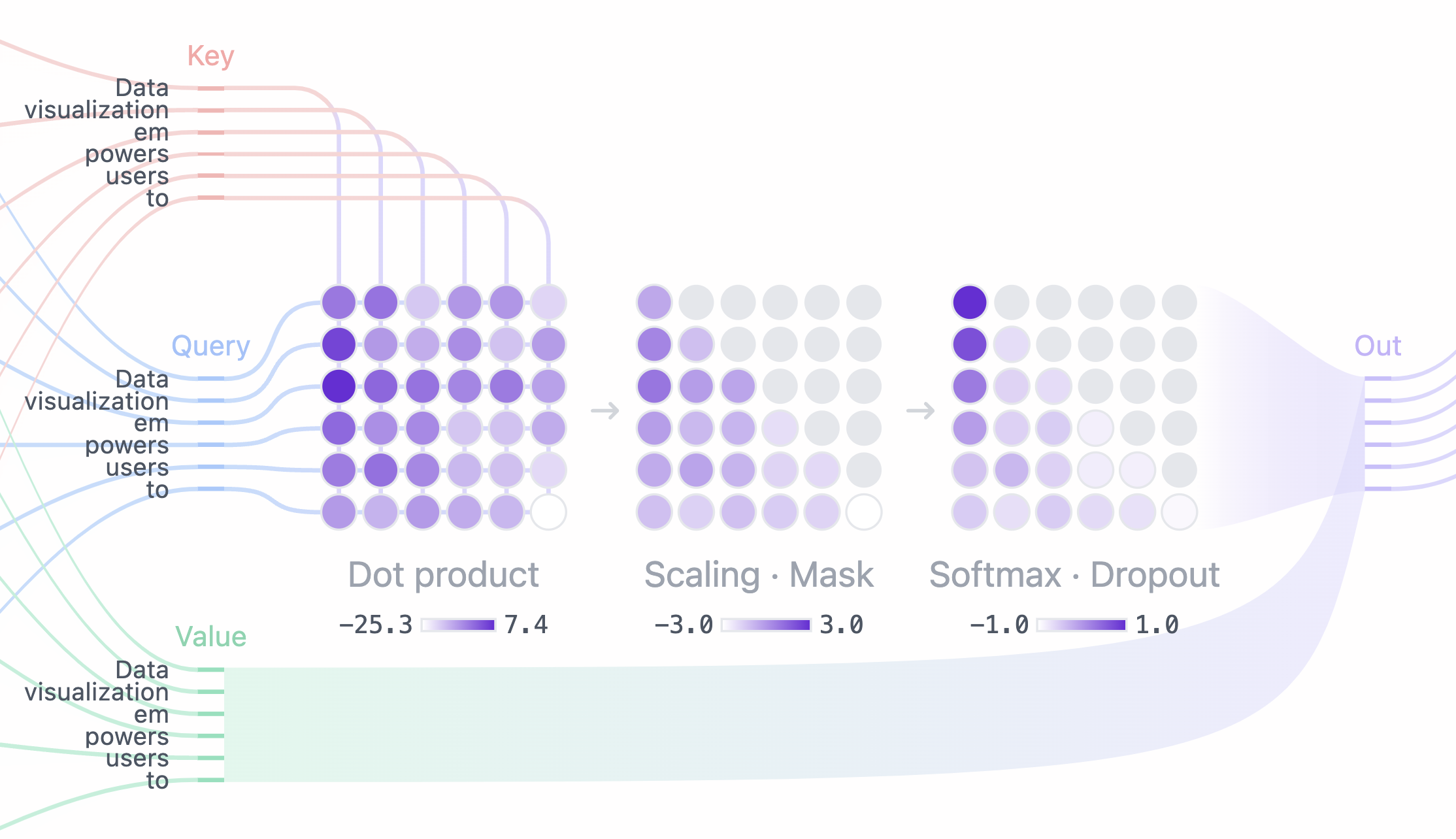 Image source: Transformer Explainer
Image source: Transformer Explainer
Here’s how it works:
- The reader asks a query: “I want info on Renaissance paintings.”
- The librarian matches the query with keys (indexes) to find the most relevant books.
- Then reads the values (book contents) of those books to find and deliver the most relevant info.
The synergy between Query, Key, and Value allows the LLM to act like a smart librarian—quickly finding and extracting relevant information.
Token
- Definition: A basic unit of text recognized by the model. It can be a word, a character, punctuation, or even part of a word.
- Analogy: If the input is a book, tokens are like the words, punctuation marks, or even syllables inside the book.
- Importance: LLMs process text as tokens. How the text is tokenized affects both efficiency and accuracy.
Example:- Input text: "The quick brown fox jumps over the lazy dog."
- Tokens: ["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]
Different tokenization methods may produce different token sequences, which can impact model performance.
Inference
- Definition: The process where the model makes predictions or generates outputs based on what it has learned.
- Analogy: The librarian gives you an answer based on their knowledge and available books.
- Importance: Inference speed, accuracy, and cost are critical to user experience.
Related concepts:
- Decoding: Converts the model’s internal representations into readable text.
- Sampling: Picks the next token from a probability distribution (e.g., Top-k, Top-p).
- Beam Search: Keeps multiple candidate sequences for better quality generation.
Inference is the “magic” of LLMs—what allows them to answer diverse questions creatively and accurately.
Parameters
- Definition: Adjustable internal variables in the model that are learned during training.
- Analogy: Think of parameters as the librarian’s “knowledge” and “skills.”
- Knowledge: What the librarian knows about books, authors, topics.
- Skills: Their ability to find, summarize, and explain information.
Examples (vLLM Parameters)
max_new_tokens: Limits output length.- Analogy: “Write a summary, but keep it under X words.”
temperature: Controls randomness in generation.- High: More creative, diverse, but risky.
- Low: More accurate, safe, but possibly boring.
- Extra Analogy: Like seasoning. High = spicy and exciting; Low = plain but safe.
top_k: Picks from the top-k most probable tokens.- Analogy: Choose the best 3 out of 10 candidate words to continue writing.
top_p: Picks from tokens that collectively make up a probability mass of p.- Analogy: Like choosing dishes from a buffet until you feel “satisfied” with the flavor profile.
repetition_penalty: Reduces repetition.- Analogy: “Don’t repeat yourself.”
num_beams: (Beam search) Maintains multiple drafts during generation.- Analogy: The librarian considers three different draft answers and keeps refining all of them in parallel.
stop: Defines stopping words or sequences.- Analogy: “Stop writing when you see '.', '!' or '?'.”
Tuning parameters is like setting the librarian’s behavior—controlling output style, creativity, and coherence.
Loss Function
- Definition: A mathematical function that measures the gap between model predictions and actual results (mainly used during training).
- Analogy: You’re training a librarian assistant. You compare their answers to your ideal answer. The bigger the difference, the bigger the “loss.”
- Goal: Minimize the loss to improve the model’s accuracy.
- Common Example: Cross-Entropy Loss.
Common Issues
Hallucination
- Definition: The model generates plausible-sounding content that’s false, misleading, or irrelevant.
- Analogy: The librarian confidently gives you an answer, but it’s completely made up—there’s no such info in the library.
- Causes:
- Overconfidence
- Poor training data
- Losing context during generation
- Mitigation:
- Use high-quality data
- Lower temperature
- Integrate RAG (retrieval)
- Human review
Hallucination is a serious LLM issue. Always verify AI-generated content.
Overfitting
- Definition: The model memorizes the training data too well, performing poorly on new or unseen data.
- Analogy: The librarian memorized every book perfectly but struggles when asked a slightly different question.
- Causes:
- Too complex a model
- Too little or unrepresentative training data
- Fixes:
- More and diverse data
- Simpler models
- Regularization (Dropout, L1/L2)
- Early stopping
Overfitting is like a “bookworm” librarian—smart, but rigid and not adaptive.
Prompt Engineering
- Definition: The art of crafting and optimizing input prompts to get better model output.
- Importance: A well-designed prompt can significantly improve model performance.
- Tips:
- Clear Instructions: Tell the model exactly what you want.
- Provide Examples: Use few-shot learning.
- Step-by-Step: Break complex tasks into smaller steps.
- Roleplay: Assign roles to the model (e.g., “You are a professional editor”).
- Analogy: Like giving the librarian clear instructions:
“Summarize this book in a professional tone and list 3 key points.”
Evaluation Metrics
- Definition: Criteria for evaluating LLM performance.
- Examples:
- Perplexity: Lower = better prediction.
- BLEU, ROUGE, METEOR: Used for translation/summarization accuracy.
- Accuracy, Precision, Recall, F1-score: Used in classification tasks.
- Human Evaluation: Manual quality checks.
- Analogy: Like performance reviews for librarians—did they answer correctly and satisfy the readers?
Special Tokens ([INST], [s], [/s])
These are structural markers used in dialogue or instruction-style models.
[INST]: Marks the start of an instruction.[s]: Start of a sentence or segment.[/s]: End of a sentence or segment.
A Day in the Library
- A reader submits a query. The librarian (LLM) uses inference to match it against keys (indexes) and retrieve values (book contents), then generates a response based on parameters. Sometimes the librarian might hallucinate or overfit. A well-crafted prompt helps get better results.
- Through user feedback and logs, we continue to improve the librarian’s knowledge and skills by adjusting parameters and enhancing training data.
References
- Attention Mechanism:Attention Is All You NeedThe Illustrated Transformer
- Tokenization:Hugging Face: Tokenizer Summary
- Training Data & Inference:Stanford CS324 Course
- vLLM Parameters:vLLM Documentation
- Hallucination:Survey of Hallucination in NLG
- Overfitting:Rethinking Generalization in DL
- Prompt Engineering:Prompt Engineering Guide
- Token Structure:LLaMA 2 Paper